Interactions in logistic regression models can be trickier than interactions in comparable OLS regression models. This is particularly true when there are covariates in the model in addition to the categorical predictors. This FAQ page will try to help you to understand categorical by categorical interactions in logistic regression models with continuous covariates.
We will use an example dataset, logit2-2, that has two binary predictors, f and h, and a continuous covariate, cv1. In addition, the model will include fh which is the f by h interaction. We will begin by loading the data, creating the interaction variable and running the logit model.
use https://stats.idre.ucla.edu/stat/data/logit2-2, clear
generate fh = f*h
logit y f h fh cv1, nolog
Logistic regression Number of obs = 200
LR chi2(4) = 106.10
Prob > chi2 = 0.0000
Log likelihood = -78.74193 Pseudo R2 = 0.4025
------------------------------------------------------------------------------
y | Coef. Std. Err. z P>|z| [95% Conf. Interval]
-------------+----------------------------------------------------------------
f | 2.996118 .7521524 3.98 0.000 1.521926 4.470309
h | 2.390911 .6608498 3.62 0.000 1.09567 3.686153
fh | -2.047755 .8807989 -2.32 0.020 -3.774089 -.3214213
cv1 | .196476 .0328518 5.98 0.000 .1320876 .2608644
_cons | -11.86075 1.895828 -6.26 0.000 -15.5765 -8.144991
------------------------------------------------------------------------------
As you can see all of the variables in the above model including the interaction term are statistically significant. If this were an OLS regression model we could do a very good job of understanding the interaction using just the coefficients in the model. The situation in logistic regression is more complicated because the effect of the covariate is nonlinear, meaning that the interaction effect can be very different for different values of the covariate. To begin to understand what is going on consider the Table 1 below.
Table 1: Predicted probabilities when cv1=50
h=0 h=1 Dprob LB UB
f=0 .1154 .5876 .4722 .2693 .6751
Table 1 contain predicted probabilities, differences in predicted probabilities and the confidence interval of the difference in predicted probabilities while holding cv1 at 50. The first value, .1154, is the predicted probability when f=0 and h=0. The second value, .5876, is the predicted probability when f=0 and h=1. The third value, .4722, is the difference in probabilities for f=0 when h changes from 0 to 1. The next two values are the 95% confidence interval on the difference in probabilities. If the confidence interval contains zero the difference would not be considered statistically significant. In our example, the confidence interval does not contain zero. Thus, for our example, the difference in probabilities is statistically significant.
We obtained all the values for Table 1 using the prvalue command, which is part of spostado. spostado is a collection of utilities for categorical and non-normal models written by J. Scott Long and Jeremy Freese. You can obtain the spostado utilities by typing search spostado into the Stata command line and following the instructions (see How can I use the search command to search for programs and get additional help? for more information about using search).
To get the values for Table 1 we will run prvalue twice; once with f=0, h=0 and once with f=0, h=1 while holding the covariate at the value 50. The first time we run prvalue we use the save option to retain the first probability. The second time we use the diff option so that we get the difference between the two probabilities.
prvalue, x(f=0 h=0 fh=0 cv1=50) delta save
logit: Predictions for y
Confidence intervals by delta method
95% Conf. Interval
Pr(y=1|x): 0.1154 [ 0.0027, 0.2281]
Pr(y=0|x): 0.8846 [ 0.7719, 0.9973]
f h fh cv1
x= 0 0 0 50
prvalue, x(f=0 h=1 fh=0 cv1=50 cv2=50) delta diff
logit: Change in Predictions for y
Confidence intervals by delta method
Current Saved Change 95% CI for Change
Pr(y=1|x): 0.5876 0.1154 0.4722 [ 0.2693, 0.6751]
Pr(y=0|x): 0.4124 0.8846 -0.4722 [-0.6751, -0.2693]
f h fh cv1
Current= 0 1 0 50
Saved= 0 0 0 50
Diff= 0 1 0 0
Next we need to step through a number of combinations of categorical variables and covariates. The code fragment below will fix the covariate at nine values between 30 to 70 while looking at differences between h=0 and h=1 separately for f=0 and for f=1.
mat P=J(2,2,.)
mat colnames P = h=0 h=1
mat rownames P = f=0 f=1
forvalues i=30(5)70 {
capture matrix drop D
display
display as txt "cv1=`i'"
quietly prvalue, x(f=0 h=0 fh=0 cv1=`i') delta save
mat P[1,1]=r(p1)
quietly prvalue, x(f=0 h=1 fh=0 cv1=`i') delta diff /* h=0 vs h=1 @ f=0 */
mat P[1,2]=r(p1)
mat temp=r(pred)
mat D=temp[2,1..3]
quietly prvalue, x(f=1 h=0 fh=0 cv1=`i') delta save
mat P[2,1]=r(p1)
/* please note: fh=1 only when both f=1 and h=1 */
quietly prvalue, x(f=1 h=1 fh=1 cv1=`i') delta diff /* h=0 vs h=1 @ f=1 */
mat P[2,2]=r(p1)
mat temp=r(pred)
mat D = D temp[2,1..3]
mat R = P,D
mat list R, title(cell probabilities, differences and confidence intervals)
}
Now, we will run the above code fragment and add annotations to the output manually with comments in bold.
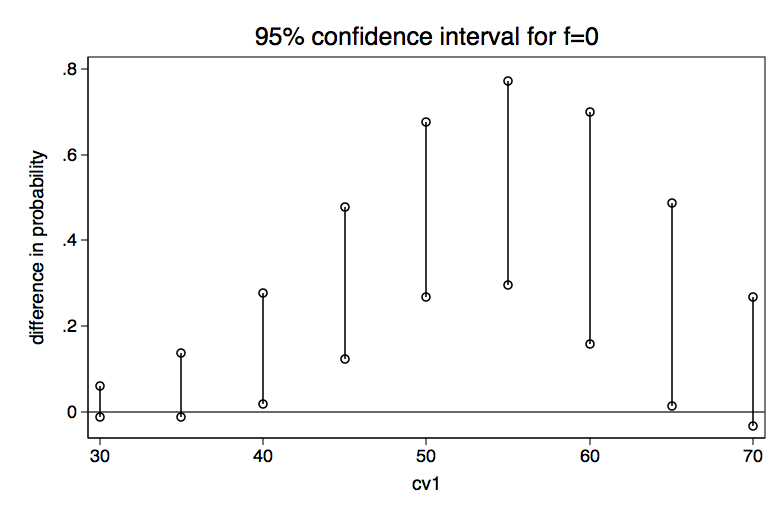
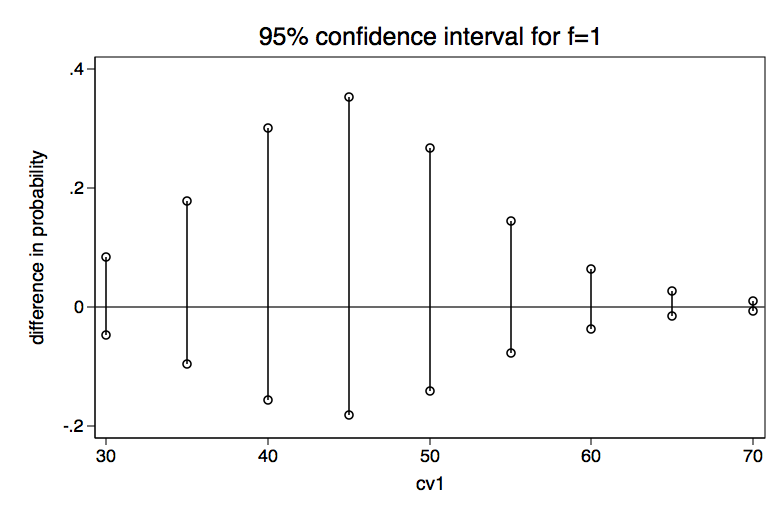
<- difference significant at f=0
cv1=30 <- hold covariate at 30
R[2,5]: cell probabilities, differences and confidence intervals
h=0 h=1 Dprob LB UB
f=0 .00255673 .02723725 .02468052 -.01224754 .06160857 <- difference not significant at f=0
f=1 .04878354 .06740873 .01862519 -.04638632 .0836367 <- difference not significant at f=1
cv1=35 <- hold covariate at 35
R[2,5]: cell probabilities, differences and confidence intervals
h=0 h=1 Dprob LB UB
f=0 .00679948 .06957896 .06277948 -.01141145 .13697041 <- difference not significant at f=0
f=1 .12047193 .16181129 .04133936 -.09505168 .1777304 <- difference not significant at f=1
cv1=40 <- hold covariate at 40
R[2,5]: cell probabilities, differences and confidence intervals
h=0 h=1 Dprob LB UB
f=0 .0179561 .16647829 .14852219 .01991065 .27713373 <- difference significant at f=0
f=1 .26784405 .34019339 .07234934 -.1564856 .30118428 <- difference not significant at f=1
cv1=45 <- hold covariate at 45
R[2,5]: cell probabilities, differences and confidence intervals
h=0 h=1 Dprob LB UB
f=0 .04656038 .34787005 .30130967 .12440741 .47821194 <- difference significant at f=0
f=1 .49419808 .57931143 .08511335 -.18160469 .35183138 <- difference not significant at f=1
cv1=50 <- hold covariate at 50
R[2,5]: cell probabilities, differences and confidence intervals
h=0 h=1 Dprob LB UB
f=0 .11537804 .58757877 .47220073 .26931943 .67508203 <- difference significant at f=0
f=1 .72295588 .78622645 .06327057 -.1399183 .26645944 <- difference not significant at f=1
cv1=55 <- hold covariate at 55
R[2,5]: cell probabilities, differences and confidence intervals
h=0 h=1 Dprob LB UB
f=0 .25834921 .7918883 .53353909 .29661155 .77046662 <- difference significant at f=0
f=1 .87452245 .90760261 .03308016 -.07776317 .1439235 <- difference not significant at f=1
cv1=60 <- hold covariate at 60
R[2,5]: cell probabilities, differences and confidence intervals
h=0 h=1 Dprob LB UB
f=0 .48196125 .91041601 .42845476 .1588636 .69804592 <- difference significant at f=0
f=1 .94901687 .96328229 .01426542 -.03588886 .0644197 <- difference not significant at f=1
cv1=65 <- hold covariate at 65
R[2,5]: cell probabilities, differences and confidence intervals
h=0 h=1 Dprob LB UB
f=0 .71303982 .96446669 .25142688 .01497498 .48787877 <- difference significant at f=0
f=1 .98028207 .98592901 .00564694 -.01520646 .02650035 <- difference not significant at f=1
cv1=70 <- hold covariate at 70
R[2,5]: cell probabilities, differences and confidence intervals
h=0 h=1 Dprob LB UB
f=0 .86904871 .98639321 .1173445 -.03299262 .26768162 <- difference not significant at f=0
f=1 .99252504 .99468476 .00215971 -.00622068 .01054011 <- difference not significant at f=1
Here is what we can say based upon the output above. There are no significant differences between the two levels of h when the covariate is held constant at either 30 or 35. When the covariate is held constant between 40 and 65 there is a significant h 0-1 difference at f=0 but not at f=1. Finally, when the covariates are held constant at 70 the h differences are not significant. It may be easier to understand these results if we graph the confidence intervals for the difference in probability separately for both f=0 and f=1.