This example is taken from Levy and Lemeshow’s Sampling of Populations.
page 167 stratified random sampling with allocation to strata
The SAS data set wvjacktwn is used in the example. A new variable called psu was added to the jacktwn data set. This variable counts the number of observations in each strata, starting with one. (In other words, the value of this variable is one for the first observation in each strata.) This variable, coded in this fashion, is necessary for use in WesVar as the VarUnit variable.
Also, a text file called jackfpc was created that contains the FPC values needed. This file was created in SAS and exported as a text file. Note that when doing this, you need to open the file in a text editor, such as Notepad or Wordpad, to ensure that there is nothing in the file other than the numbers. Many programs, when creating such a text file, will put the variable name on the first line. This variable name, and any other text, needs to be deleted before the file can be used in WesVar.
In this example, the variable sampwt is used as the weight variable, the variable psu is used as the VarUnit, the variable stratum is used as the VarStrat variable and the variable twin is used as the analysis variable. The variable quart1 is used to make the table. The jackknife-n (jkn) method of creating the replicate weight is used because we have more than two PSUs per stratum.
The output is given below.
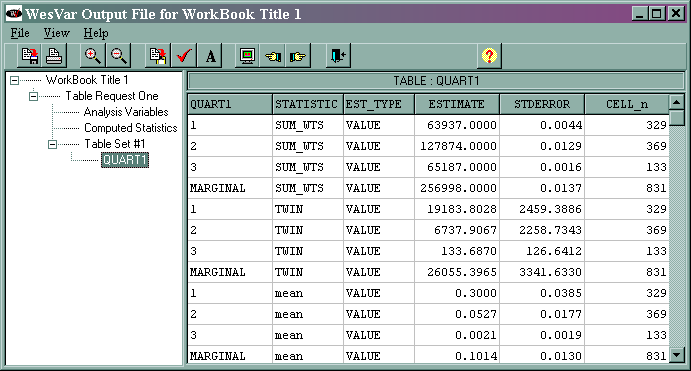
The marginal sum_wts value of 256998 is the estimated population total. The marginal twin value of 26055.3965 is the estimated total of the variable twin, and its standard error is 3341.6630. The marginal mean value of 0.1014 is the estimated mean of the variable twin, and 0.0130 is its standard error. The standard error for the total and the mean are different from those produced by SUDAAN and Stata. We are uncertain as to the cause of the difference.