Research, from hypothesis development through finished manuscript, is a process. Hence, the results section of the manuscript is the product of all of the earlier stages of the research. The better the quality of these earlier stages, the better the quality of the results section.
The main points
- Plan, plan, plan, plan!
- Tell a cohesive, concise story.
- Clearly state your hypotheses and how your analyses address each hypothesis.
- Provide enough detail such that your audience can understand what you did and why you did it.
Other tips
- Planning is important (power analysis, classes, statistical software packages).
- The more you understand about a statistical technique, the easier it is to describe your results to others.
- Practice analyzing, interpreting and writing about results with practice datasets. They are available in most (all?) statistical software.
- The “distance” between getting your results and being able to write about them increases with the complexity of the analysis (i.e., the type of statistical technique that you are using) and the complexity of the model.
- Try the “Grandma” technique.
- There is no relationship between the amount of time it took you to do something and the amount of space on the page its write-up gets.
- Remember that there is a careful balance between enough detail to replicate the experiment and space limitations imposed by the journal.
- Check for updated reporting standards (APA guidelines, exact p-values, no “stat sig”, meta-analysis, SEM, etc.).
Where to start
The results section usually contains two parts: the descriptive statistics and the analyses. These two parts should be closely related. For example, you probably don’t want to describe variables that won’t be used in the analyses. This can confuse your audience and wastes valuable space. Be sure that all of the variables used in the inferential statistics section are included in the descriptive statistics.
Descriptive statistics
The descriptive statistics are important because this is often the vehicle by which your variables are introduced to your audience. You can think of this part as introducing one friend to another. Of course, different types of descriptive statistics are used for different types of variables.
Continuous variables
- ordinal or continuous
- number of valid (non-missing) values
- mean and standard deviation
- perhaps median
- range
- perhaps correlations with other continuous variables (without p-values)
- perhaps histograms
Categorical variables
- frequency of each level (including missing)
- perhaps crosstabs with other categorical variables (without p-values)
- perhaps bar charts
Nominal v. ordinal (outcome v. predictor)
Count variables (outcome v. predictor)
The above points are merely suggestions. If you have one or more grouping variables, such as a main predictor variable that is categorical, you may wish to provide Ns, means, and standard deviations for each group. Such values are often used in meta-analyses, which are becoming more popular, as are quality checklists, which tend to give higher ratings to papers which provide more thorough descriptive statistics.
The use of p-values should be avoided in this section. Descriptive statistics are just that: they describe your sample of data. P-values necessarily mean that a hypothesis has been tested. When describing data, though, there is no hypothesis to be tested, so no p-value should be given. Including p-values in descriptive statistics also contributes to an alpha inflation problem. This problem is discussed later in this workshop.
Inferential statistics
In the analysis part of the results section, you will want to describe your specific hypothesis, the statistical technique that you will be using, and the model (e.g., outcome and predictor variables). This is especially important when your hypothesis involves an interaction. Clearly stating the relationship between your hypothesis and the statistical technique and model is important for several reasons. First, it helps guide your audience through this part of the results section. Second, this connection will make the substantive interpretation of the results easier. Third, it is a good way to keep track of how many tests are being run. Fourth, if each test is associated with a hypothesis, you won’t run any tests “just because”.
For commonly-used techniques, such as ordinary least squares regression, your description may be as short as a single sentence. For more complicated techniques or when using a technique that is likely unfamiliar to your audience, more description (and explanation) may be required.
Describing the model-building process is also important. Describe how the predictor variables for the model were selected. Were these predictors selected based on your theory (which may have been informed by the literature), because these variables were statistically significant in intermediate models, because these variables were statistically significant in bivariate analyses, or some other reason?
In times past, many researchers (and indeed, many authors of well-regarded statistical texts) used intermediate models to work their way towards a final model. Predictor variables that were statistically significant in these intermediate models were retained; predictor variable that were not statistically significant were dropped. In a way, it was a type of stepwise regression. However, researchers started to realize that there were very serious problems with developing models via stepwise regression. One of the most important problems is that models developed via stepwise regression tended to not generalize well from the sample to the population. This is because stepwise regression takes advantage of peculiarities in the dataset at hand. The solution is to let your theory decide which predictors should be included in your model. These predictors stay in the model even if they are not statistically significant. The approach minimizes the need for intermediate models.
You do not want to present your results as if you ran only the models presented in the paper if you actually ran many more models than you discuss in your paper. This is related to the alpha-inflation problem: the p-values are interpreted differently if there are a few of them or lots of them. For example, if you run only two tests on your dataset and report those (statistically significant) p-values, it is likely that there really is only a 5% chance that one or both of the p-values are false alarms. However, if you ran 50 tests and reported the only two that were statistically significant, it is very likely that you have reported false alarms. Another way to understand this is to realize that those two tests may not be statistically significant in other samples of data (of the same size).
If there are categorical variables in your model, clearly state how they were handled (e.g., reference category, coding scheme, specific hypothesis).
Most models make assumptions, and you should mention that the assumptions were assessed, but the result of each diagnostic test is usually not included. If one or more assumptions are grossly violated, further discussion may be warranted.
It is not uncommon to mention which statistical package (and which version of the package) was used to conduct the analysis.
Usually, the analyses are ordered from most to least important, except when this will disrupt the flow of your story. If there are more than a few analyses, indicate whether an alpha control procedure was used, and if so, which one.
Almost all studies have at least some missing data. You will want to indicate how the missing data were handled (e.g., listwise deletion, complete cases analysis, maximum likelihood techniques, multiple imputation, etc.).
Many journals also require or encourage researchers to include measures of effect sizes and their standard errors. You need to be very specific about which measure of effect size you have used, because there are dozens of them. You also need to include the standard error of the effect size. Remember that effect sizes are also estimates obtained from your data, so the standard error around the effect size is just as important to report as the standard error around your point estimates.
You should report the exact p-value as given in the output from the statistical software, rather than merely stating that the result is statistically significant or not. This represents a change from the advice given 20 years ago. At that time, p-values were often estimated by looking them up in the back of statistics text, so reporting an exact p-value was often not even possible. However, it was noted that the exact p-value itself did not matter; all that was important was whether or not the result was statistically significant. While it is still true that the exact p-value is not terribly important, it can be useful when researchers include your paper in their meta-analysis and the p-value is used to help calculate an effect size.
Some journals (and in fact, some restricted datasets) discourage researchers from discussing results in terms of statistically significant and not statistically significant. Instead, the emphasis is put on the size of the effect and how impactful an effect of that size is in the “real world”. This is a much more thoughtful, but often more difficult, way to interpret and write about results. The advice in this area is still evolving, so please check on it every year or two. A good place for this information is from the American Statistical Association (https://www.amstat.org/ ).
You should report the overall test of the model. If the overall model is not statistically significant, you do not want to interpret any of the coefficients.
If you conducted an a priori power analysis, you will want to describe it. This description will include details about the assumptions that you made when running the power analysis, such as what effect size was assumed and a justification for that assumption. For example, you may have estimated your effect size from pilot data, from reported studies in the literature, or decided on a minimum effect size of interest.
Ideally, there will be at least a few days between the time that you finish writing and the time the article (or poster) is due. Rereading your article after setting it aside for a while is a great way to catch errors and to check for consistency. It may also be helpful to have a colleague read it over.
One final topic that I would like to cover before we move on to examples is measurement. Andrew Gelman wrote “For my money, the #1 neglected topic in statistics is measurement.” (https://statmodeling.stat.columbia.edu/2015/04/28/whats-important-thing-statistics-thats-not-textbooks/ ) Including descriptions about how variables were measured is always a good idea.
Examples
After I presented this workshop last time, I found that what most people in the audience wanted was specifics, especially what to say and what not to say in the results section. In fact, many people said they wanted to be shown an output, say of a regression analysis, and then an example of how to write it up. Unfortunately, this is nearly impossible to do, and I will show you why in just a moment. Besides, this “cookie-cutter” approach is usually a very bad way to go. I don’t like to see people doing statistics this way, and this approach is even worse when you are writing results. The best way to write a clear, concise results section is to thoroughly understand the statistical techniques that you used to analyze your data. Another good strategy is to look at texts in your field that report similar analyses for ideas about the exact terminology to use. This is a particularly good idea because the write-ups of similar analyses can be very different in different fields. Also, some journals require much more precise language than other journals, so you might want to look at some articles in the journal in which you want to publish. You can also find examples in our Data Analysis Example pages, our Annotated Output pages, and Regression Models for Categorical Dependent Variables Using Stata, Third Edition by Long and Freese (2014). Even if you are not analyzing your data with Stata, this is a great resource. Another very good book with lots of information on interpretation is Introduction to Mediation, Moderation, and Conditional Process Analysis: A Regression-based Approach, Second Edition, by Andrew F. Hayes (2018). Michael N. Mitchell’s book Interpreting and Visualizing Regression Models Using Stata, Second Edition (2020) has great information regarding all types of coding schemes for categorical variables, interpretation of coefficients and ways to visualize results.
Let’s start off with a couple of examples of why you can’t just look at a piece of output and write about it. After that, we will look at some examples of some common pitfalls encountered when writing up the results of seemingly simple analyses.
So, here is a regression table. The variable gender is dichotomous, and the variable read is continuous. What could be difficult about interpreting this?
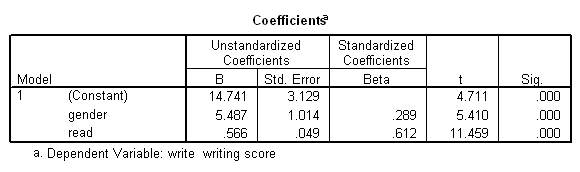
The difficulty has to do with the way the dichotomous variable gender is coded. If gender was coded as 0 and 1, then the intercept is the mean for the group coded 0 when the reading score is equal to 0. If gender is coded 1 and 2, then the intercept is the mean for the group coded 1 minus the coefficient (the B, 5.487) for gender when reading is equal to 0. If gender is coded -1 and 1, then the intercept and the coefficient for gender are interpreted in a third way. The predictor variable read could also be included in the model in its original metric, centered or standardized. Note that despite the changes in the coding of the predictor variables, the overall model is the same; the model is just be reparameterized in different ways.
Now, let’s take this example one step further. Let’s say that we create a variable called female, which is 1 for females and 0 otherwise (i.e., 0 for males). Let’s replace gender with female, and let’s also include the interaction between female and read.
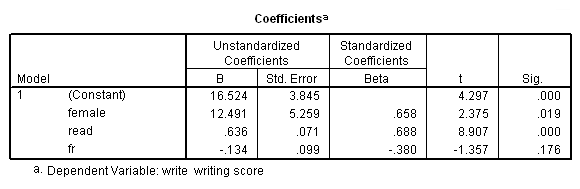
How would you interpret these results? Well, the interaction, fr, is not statistically significant, so there isn’t much we can say about that. A common question is whether the statistically non-significant interaction term should remain in the model. This question depends on your training and your hypotheses.
When the categorical predictors are coded -1 and 1, the lower-order terms are called “main effects”. When the categorical predictors are coded 0 and 1, as they almost always are in regression models, the lower-order terms are called “simple effects”. This distinction is important because simple effects are interpreted differently than main effects.
The important point here is that how you code your variables affects how you interpret their coefficients in the output. Therefore, you want to use methods of coding that yield the kind of interpretation you would like to make. While our example illustrated coding of a dichotomous variable, you also have options with regard to the coding of continuous variables. For example, if you want the constant to have a different meaning, you can center the continuous predictor variable.
Including a graph of the interaction is usually a good idea. Most statistical software packages will make such a graph. I strongly suggest making the graph, whether or not it is included in the paper, because this graph is as helpful to the researcher in understanding the interaction as it is to the audience. Also, it is really difficult to “see the whole picture” based on the interpretation of a single (or multiple) coefficient(s) of the interaction, and the coefficient of the interaction term is the mostly likely term in the model to be misinterpreted.
The point here is that simply looking at the output is often not enough when trying to do interpretation and writing. Rather, you need to know lots of things, and seemingly small details can greatly affect the meaning. This is why the “cookie-cutter” approach to interpretation doesn’t work well. Now let’s go on to some other examples of places where people often have difficulty in writing about results.
A common error when working with regression models is to refer to the model above as a multivariate regression instead of a multiple regression. A multivariate regression is a regression model with more than one outcome variable; a multiple regression is a regression with more than one predictor variable.
Example: Categorical predictor variables
Now let’s look at a model that includes a categorical variable that has more than two levels. In this example, we have included the variable race, which has four levels. Because race has four levels, we have included three dummy variables (i.e., variables coded 0 and 1) in the regression. The dummy variable for the second level of race is statistically significant, while none of the other dummy variables are. What can we say about this?
regress write read math female i.race
Source | SS df MS Number of obs = 200
-------------+------------------------------ F( 6, 193) = 37.46
Model | 9619.24508 6 1603.20751 Prob > F = 0.0000
Residual | 8259.62992 193 42.79601 R-squared = 0.5380
-------------+------------------------------ Adj R-squared = 0.5237
Total | 17878.875 199 89.843593 Root MSE = 6.5419
------------------------------------------------------------------------------
write | Coef. Std. Err. t P>|t| [95% Conf. Interval]
-------------+----------------------------------------------------------------
read | .320763 .0612872 5.23 0.000 .1998843 .4416416
math | .3652081 .067842 5.38 0.000 .2314011 .4990151
female | 5.287456 .937736 5.64 0.000 3.43793 7.136983
|
race |
2 | 4.838573 2.45403 1.97 0.050 -.0015891 9.678734
3 | .9289412 1.989441 0.47 0.641 -2.994896 4.852778
4 | 2.490295 1.493206 1.67 0.097 -.4548022 5.435392
|
_cons | 11.74903 2.984052 3.94 0.000 5.863487 17.63457
------------------------------------------------------------------------------
What we can say about this depends on your hypothesis and your training. If the hypothesis is about the variable race, then we can’t say anything about the comparisons of the various levels of race until we know if the variable race as a whole is statistically significant or not. The 3 degree of freedom test below (AKA the omnibus test) indicates that it is not, so we can’t say anything about the difference between level 2 and level 1 of race. On the other hand, if you had an a priori hypothesis regarding the test between Hispanic (the reference group) and Asian (2.race), you could interpret the result above and ignore the 3 degree of freedom test below.
testparm i.race
( 1) 2.race = 0
( 2) 3.race = 0
( 3) 4.race = 0
F( 3, 193) = 1.67
Prob > F = 0.1757
Now let’s change the model a little bit (replace math with socst) and see what happens.
regress write read socst female i.race
Source | SS df MS Number of obs = 200
-------------+------------------------------ F( 6, 193) = 38.06
Model | 9689.26202 6 1614.877 Prob > F = 0.0000
Residual | 8189.61298 193 42.4332279 R-squared = 0.5419
-------------+------------------------------ Adj R-squared = 0.5277
Total | 17878.875 199 89.843593 Root MSE = 6.5141
------------------------------------------------------------------------------
write | Coef. Std. Err. t P>|t| [95% Conf. Interval]
-------------+----------------------------------------------------------------
read | .3307708 .0592551 5.58 0.000 .2139001 .4476414
socst | .3074725 .0553338 5.56 0.000 .198336 .4166091
female | 4.690728 .9393554 4.99 0.000 2.838008 6.543449
|
race |
2 | 7.55963 2.399498 3.15 0.002 2.827024 12.29224
3 | .2886157 1.981522 0.15 0.884 -3.619603 4.196834
4 | 3.043909 1.47917 2.06 0.041 .1264957 5.961323
|
_cons | 14.17782 2.780192 5.10 0.000 8.694361 19.66128
------------------------------------------------------------------------------
testparm i.race
( 1) 2.race = 0
( 2) 3.race = 0
( 3) 4.race = 0
F( 3, 193) = 4.26
Prob > F = 0.0061
Now the overall test of race is statistically significant, and you can interpret the results in the regression table above.
When writing about the dummy variables, you will want to make clear what type of coding system was used (e.g., dummy coding, effect coding, orthogonal polynomial coding, etc.), as well as what the reference group is. Both of these will affect the interpretation of the dummy variables. Also, you don’t want to leave out dummy variables that are not statistically significant; for example, you would not want to rerun the above model without the third level of race. If you did that, your reference group would be a combination of the first and third levels of race, and that is not likely to make substantive sense.
For more information about coding systems, please see chapter 5 of our Regression with SAS , Stata and SPSS web books.
Another error to avoid when working with nominal predictor variables is including the variable in your model as if it was a continuous predictor. You can ensure that you have not made this mistake by reporting the multi-degree-of-freedom (AKA omnibus) test of the variable.
Example: Logistic regression

If you have conducted a logistic regression, you can describe your results in several different ways. You could discuss the logits (log odds), odds ratios or the predicted probabilities. Which metric you choose is a matter of personal preference and convention in your field. Most of the information in this section is quoted from Regression Models for Categorical Dependent Variables Using Stata, Second Edition by Long and Freese (2006), pages 177-181. If you are running a logistic regression model, an ordered logit model, a multinomial logit model, a Poisson model or a negative binomial model, I strongly suggest that you borrow or buy a copy of this book and read up on the particular type of model that you are running. Most people find this book very helpful, even if they are using a statistical software package other than Stata.
When interpreting the output in the logit metric, “… for a unit change in xk, we expect the logit to change by k, holding all other variables constant.” “This interpretation does not depend on the level of the other variables in the model.”
When interpreting the output in the metric of odds ratios, “For a unit change in xk, the odds are expected to change by a factor of exp(k), holding all other variables constant.” “When interpreting the odds ratios, remember that they are multiplicative. This means that positive effects are greater than one and negative effects are between zero and one. Magnitudes of positive and negative effects should be compared by taking the inverse of the negative effect (or vice versa).” “For exp(k) > 1, you could say that the odds are “exp(k) times larger”, for exp(k) < 1, you could say that the odds are “exp(k) times smaller.””
Now if you are having difficulty understanding a unit change in the log odds really means, and odds ratios aren’t as clear as you thought, you might want to consider describing your results in the metric of predicted probabilities. Many audiences, and indeed, many researchers, find this to be a more intuitive metric in which to understand the results of a logistic regression. While the relationship between the outcome variable and the predictor variables is linear in the log odds metric, the relationship is not linear in the probability metric. Remember that “… a constant factor change in the odds does not correspond to a constant change or a constant factor change in the probability. This nonlinearity means that you will have to be very precise about the values at which the other variables in the model are held.”
I hope that this example makes clear why I say that in order to write a clear and coherent results section, you really need to understand the statistical tests that you are running.
Our next example concerns confidence intervals, so let’s jump ahead a little bit and talk about confidence intervals in logistic regression output. “If you report the odds ratios instead of the untransformed coefficients, the 95% confidence interval of the odds ratio is typically reported instead of the standard error. The reason is that the odds ratio is a nonlinear transformation of the logit coefficient, so the confidence interval is asymmetric.”
Example: Confidence intervals
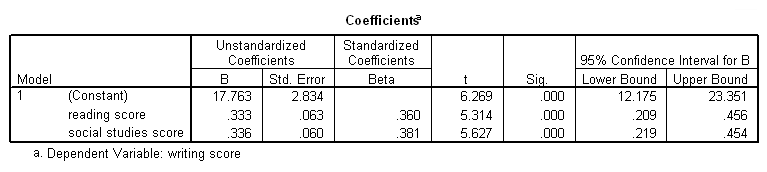
Many journals are pushing for confidence intervals to be included in the results section. But what does the confidence interval tell you? Problematic interpretations include: “We are 95% confident that the true parameter for reading score lies between .209 and .456.” “There is a 95% chance that the true parameter lies between .209 and .456.”
In fact, the confidence interval gives a range of values such that if the experiment was run many times (e.g., 10,000 times), the range would contain the true parameter 95% of the time. Most of the time, there is little reason to comment on the confidence interval: it is what it is. One situation in which you might want to comment on the confidence interval is when you are conducting a study in order to get a precise estimate of a particular parameter, e.g., the mean age of people in a particular population.
Also, if a confidence interval is particularly large, it may indicate that there is a problem, and it is worth investing. Super large confidence intervals will likely catch the attention of a journal reviewer (or a dissertation committee member), so be prepared to explain why the confidence interval is so large and not an indication of a problem.
Example: Interaction terms
Many researchers have difficulty interpreting and understanding the meaning of interaction terms in statistical models, so this is often one of the most challenging parts of the results section to write. If you are going to include an interaction term in your model, be sure that it is testing a hypothesis of interest to you; don’t include interactions “just because”. Also, plan on spending extra time exploring and graphing the interaction. This is one term in your model that you are going to have to understand really, really well before you will be able to write about it clearly. Also, some statistical software packages are better than others for creating the graphs of interactions, so you may need to switch packages to make the graph. Graphs are often a necessary part of understanding the interaction, even if the graph won’t be included in the final manuscript.
The simplest form of interaction to interpret is the interaction of two dichotomous variables. It is fairly easy to get the cell means, see how the coefficients are calculated, and obtain a graph. The situation becomes more complicated when you have a dichotomous by continuous interaction. In this situation, graphs are usually very helpful in understanding what is happening. When you have a continuous by continuous interaction, the graph is three dimensional, and you are looking at the warping of a plane. The situation becomes even more complex if you have more than one interaction in the model or three-way (or higher) interactions. Please remember that if you have interaction terms in your model, you almost always need to have the lower-order effects in the model as well. For example, if you have a three-way interaction of xyz, you will need to include in the model the three two-way interactions, xy, yz and xz, as well as x, y and z. If all of the lower-order terms are not included in the model, the three-way interaction will likely be uninterruptible.
For more information regarding the use and interpretation of interactions in regression, please see the last few chapter of our OLS Regression with SAS , Stata and SPSS web books.
For more information on interactions in logistic regression, please see our seminar Visualizing Main Effects and Interactions for Binary Logit Models in Stata .
Example: Bivariate tests
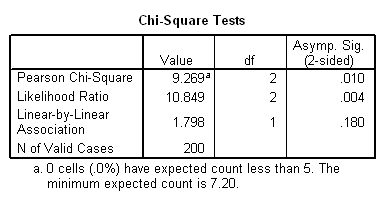
For our last example, let’s talk about the clarity of specifying which statistical test was conducted. Looking at the output above, a researcher might write, “We did a bivariate analysis, and the result was significant (p = .01).” However, this is problematic for a couple of reasons. First of all, a “bivariate” analysis can refer to any analysis that involves exactly two variables. Examples of bivariate analyses include chi-square, correlation, simple OLS regression, simple logistic regression, t-test, one-way ANOVA, etc. Second, the write up should be specific about which variables are used in each analysis. Perhaps a better way to write this would be: “We conducted a chi-square test with gender and favorite flavor of ice cream, and the result was statistically significant (χ2(2) = 9.269, p < .05).” Depending on the rest of the paragraph, you might also want to include the number of cases used in this analysis, the number of cases in each cell, and/or that the assumption that each expected count was five or greater was met.
Words of caution
While I can’t tell you exactly what words to use in your results section, we have come up with a partial list of words that you want to be very careful when using. One of the problems with many of these words is that they have at least two meanings: a meaning in common parlance and a specific statistical meaning (and sometimes more than one statistical meaning).
- proved/proven
- chance
- odds
- risk
- probability
- significance (statistical or “real world”, parameter or model)
- likelihood
- beta (standardized or unstandardized regression coefficient)
- standardized (variable, coefficient, test scores)
- normal
- controlling for or adjusting for (this is an idea that is in the analyst’s head, not the program analyzing the data)
- covariates (continuous predictors v. all predictors )
- robust (regression, standard errors, findings)
- nested (models, data)
- hierachical (models, e.g., multilevel modeling, blocked regression, data)
- random (variables, intercepts, slopes, effects)
- datum is; data are
- strata (complex survey data v. survival analysis; survival analysis with complex survey data)
Tables and graphs
Returning to the point about space issues, tables and graphs are two ways to convey a lot of information in a relatively small amount of space. However, creating useful tables and graphs is often more difficult than it seems. Almost everyone has had the experience of reading a journal article and being mystified about what exactly is in a particular table or how some values where calculated. It is often tempting and easy to add too much information in a single table; the old adage “less is more” is often true.
Tables and graphs can be included in either the descriptive part of the results section, the analysis part or both. Of course, you want to use these methods of conveying information very judiciously. (In other words, you probably can’t have more than a few tables and/or graphs in your manuscript.)
Here are a few general tips for creating tables (quoted from Lang and Secic, How to Report Statistics in Medicine: Annotated Guidelines for Authors, Editors, and Reviewers, Second Edition, 2006, chapter 20).
- “Tables are for communication, not data storage.” (Howard Wainer)
- “Tables multitask about as well as humans; the simpler the task, the more you can multitask.”
- “Tables should have a purpose; they should contribute to and be integrated with the rest of the text.”
- “Tables should be organized and formatted to assist readers in finding, seeing, understanding, and remembering the information.”
- “Organize the table visually as well as functionally.”
- “Data presented in tables should not be duplicated elsewhere in the text.”
Here are a few general tips for creating graphs (quoted from Nicol and Pexman, Displaying Your Findings: A Practical Guide for Creating Figures, Posters, and Presentations, 2003).
- include only essential information
- black and white only; no color (journal v. web)
- understandable on its own; all information needed to understand each element (such as abbreviations and definitions) should be included in the caption
- in most cases, three dimensional graphs should be avoided
- when possible, legends should be in the figure image
- when possible, axis labels should be parallel to the axis
- the dependent variable is usually presented on the y-axis
- should follow the rules of capitalization that are specific to captions
- the y-axis should be 2/3 to 3/4 the length of the x-axis
- the highest values on the axes should be higher than the highest data values
- grid lines, if used, should not be too close together
- symbols marking data points or plot symbols are about the same size as the smallest lower case letters in the graph
- axis scales (labels) should not be misleading (e.g., a small difference should look small)
- font sizes should not vary by more than four points
- figures are referenced in the text using the figure number
If you have a very large data set, graphing anything can be a challenge. You may want to look at Graphics of Large Data Sets: Visualizing a Million by Unwin, Theus and Hofmann (2006). They offer some useful tips on making graphs with a large number of data points more readable. Other types of figures, such as a relief maps, schematics of the research design or drawings that were used as stimuli in the experiment, are sometimes presented in research publications. The texts listed above have some tips for making these as useful as possible to your audience.
Some things to avoid
There are a couple of things that you want to avoid in your results section.
One is false precision. As a general rule, two digits after the decimal is enough. In fact, rounding (when presenting results, not when conducting the analyses) can often help your audience better understand your results.
Avoid concluding that one result is “more significant” than another result because, for example, one p-value is .02 and the other is .0001. There is no such thing as one result being “more significant” than the other. If you are interested in relative importance, you want to look at effect sizes, but certainly not p-values.
Another pitfall to avoid is claiming that a result is “almost significant” or “nearly significant” when the p-value is .055 or so. These terms are just different ways of saying non-significant. Also, according to Murphy’s Law, the p-value of .055 will be associated with the variable in which you are most interested. Please avoid “adjusting” your model so that you get the p-value that you want (one that is less than or equal to .05). You can say that a result with a p-value of .055 is suggestive and that future research may want to follow up on this, but not significant is not significant, and you have to consider the role random chance played in obtaining that p-value.
While we are on the topic of non-significant results, a good way to save space in your results (and discussion) section is to not spend time speculating why a result is not statistically significant. Because of the logic underlying hypothesis tests, you really have no way of knowing why a result is not statistically significant. Once you find that something is statistically non-significant, there is usually nothing else you can do, so don’t waste your time or space there; rather, move on and talk about something else. Some really persistent analysts try to do post-hoc power analyses when faced with non-significant results, but there is a large literature explaining why these are neither appropriate nor useful. Excellent summaries can be found in Hoenig and Heisey (2001) The Abuse of Power: The Pervasive Fallacy of Power Calculations for Data Analysis and Levine and Ensom (2001) Post Hoc Power Analysis: An Idea Whose Time Has Passed?. As Hoenig and Heisey show, power is mathematically directly related to the p-value; hence, calculating power once you know the p-value associated with a statistic adds no new information. Furthermore, as Levine and Ensom clearly explain, the logic underlying post-hoc power analysis is fundamentally flawed.
The changing thinking regarding p-values
In recent years, many statisticians have advocated for a rethinking of the use of p-values in research. A few suggest doing away with p-values completely while most suggest down-grading their importance. Many want to do away with the phrase “statistically significant” and replace it with a discussion of whether or not the observed effect is large enough to be meaningful in the “real world”. In many situations, this is easier said than done. For example, most researchers would agree that a correlation of .9 is important in the “real world”, and a correlation of .001 is not important in the “real world”, but what about all of the values in between those? At what value does the correlation become meaningful in the “real world”? You can ask a similar question about differences in means between groups (and what about the standard error around those means?). These are the simplest and easiest of examples. This is yet another reason that you really need to understand the statistical procedures that you are using, because you need to have some sense of what plausible values might be. Effect sizes are helpful in this situation, but effect sizes have not been defined for all analyses. For example, as of now, there are no agreed-upon effect size measures for count models, linear multilevel models, or most analyses that use weighted data. Also, remember that all of these are “effects” that are measured in a single dataset, and therefore some measure of variability is often required.
Important issues
1.) Missing data: Missing data issues and the possible ways of handling them can take a lot of time. You not only have to learn about the pros and cons of various possible techniques, but then you have to decide which one is most appropriate for your situation. You will find that hard-and-fast rules are rare in this area, and there is lots of disagreement among “experts”. Furthermore, the advice changes over time as new techniques are developed and pitfalls with older techniques are discovered and explored. Once you have decided on a technique, you will have to determine if the statistical software package with which you are familiar will do what you want, or if you will then have to find and learn a package that will do that. Next, you need to determine if the package that you want to use for the analysis will handle that type of imputation. For example, let’s say that you were doing a multiple linear regression in SPSS. That was fine until you decided to use full information maximum likelihood (FIML) to handle your missing data.
2.) Small sample sizes: For most applied research, small sample sizes are problematic, usually for many reasons. Of course, the first question is: What is small? There is no one answer for this question, just as there is no single answer for the question: Is my sample size sufficient? Returning to the issue of small sample sizes, one reason that they are difficult is because it is often difficult to get a random and representative sample if the sample size is small. Second, many common statistical procedures (e.g., maximum likelihood procedures, EFA, correlations) are not appropriate for small sample sizes. Even if the researcher decides to use the modeling technique, the model may not run for numeric reasons, the model may not converge, a matrix may not be positive definite, etc. Even if the model does run successfully, the assumptions of the test may not be met or may be “fragile”. Any of these problems can cause the researcher to either modify the model until it does run, or “fall back” to a simpler statistical technique. This can really complicate things because now you have to ask a modified form of your research question, then the flow of the research is disrupted, etc. In other words, your hypotheses are necessarily tied to your statistical analyses, and you usually cannot modify one without modifying the other. Also, issues of fair and accurate reporting of what you have done become pertinent.
3.) Alpha inflation/multiplicity: Alpha inflation is a phenomenon that happens when you conduct more and more significance tests on the same data set. I am going to use an extreme example to illustrate the problem. Let’s say that you run only one significance test on your data and that you have set alpha equal to .05. This means that, five times out of 100, you will get a statistically significant result when, in fact, there is no effect in the population. In other words, you have a 5% chance of rejecting the null hypothesis when it is true. Now let’s say that you ran 10 tests. The formula for determining the nominal alpha level is: 1 – (1 – alpha)x, where x is the number of tests that you run. So we have 1 – (1 – .05)10 = .40. This means that there is a 40% chance that you will get a Type I error (AKA a false alarm), not a 5% chance.
To address this problem, many researchers use alpha correction procedures (which can create their own set of problems), but you can see that you want to run as few significance tests as possible to minimize this problem. This topic also ties back to our earlier discussion about planning. You want to know ahead of time how many significance tests you will be running. There is also an issue of fair and accurate reporting of what you have done here. You want to run only the tests that you planned to run, and not go fishing for statistically significant results. As an extreme example, you would not want to run 100 t-tests and report only the few that were statistically significant. The reader of your article or dissertation assumes that you have reported all relevant aspects of what you have done, and omitting the fact that you ran 97 more significance tests than you reported is an important omission, as your results should be interpreted very differently in light of how many tests your ran. Remember that the reproducibility of published results is of paramount importance to the advancement of any discipline, and accuracy about the type and quantity of analyses performed is an important aspect of reproducibility of your results. Frank E. Harrell, Jr. discusses this topic in his book Regression Modeling Strategies, Second Edition (2015). He also discusses “phantom degrees of freedom”. Yes, they are as spooky as they sound!
4.) Complex survey data: Many researchers who have never used complex survey data before believe that analyzing this type of data is just like analyzing data from experiments or quasi-experiments. This isn’t true. The sampling weights need to be used to adjust the point estimates for the sampling plan, and the standard errors need to be adjusted to account for the non-independence of the observations (i.e., PSUs and/or strata or replicate weights need to be used). For some researchers, this simply means using different commands in the statistical software package that they are already using (such as Stata). For others, it means learning a new statistical software package. Also, not all procedures that are available for experimental data are available for complex survey data.
5.) Correlated data: Now, technically, most complex survey data are correlated data. However, there are many types of correlated data that are not survey data. For example, patients or doctors nested in hospitals, people nested in neighborhoods, partners nested in couples, etc. There are several ways to analyze correlated data, and it is often a judgment call on the part of the analyst as to which technique to use. Again, if you are not familiar with the various ways to analyze correlated data you will have to stop and learn at least enough about the various methods so that you can select which method you feel is most appropriate to use. When writing about the analysis, you will have to justify why you selected this technique over others. Also, you may end up having to analyze the data using more than one technique so that you can have confidence in your results.
The use of the web
The final topic that I want to discuss today has to do with possible future trends in research and how they might affect you. Some researchers have started making their data sets (real or synthetic), codebooks and syntax available on their web sites. In a similar vein, some journals are asking for copies of data sets and making them available on their web sites so that other researchers can use them as secondary data sets or to confirm published results. Either way, this trend means that there may be much closer scrutiny of data sets and their analysis. We always suggest that researchers use syntax (as opposed to point-and-click) to run their analyses. There are at least two good reasons for this. Such syntax files can be very useful if you get a revise and resubmit (“R&R”) or for posting on a web site. This will also document your data transformations, analyses and thought process. Even if you are not planning on making your data set publicly available, you should keep careful notes about each step in your research and data analysis, including how and why each step is done.
Additional resources
I hope that these tips will help make the writing of the results sections of papers easier. If you are interested in viewing the resources mentioned in this presentation, the links are:
- Data Analysis Examples
- Annotated output
- Web books
Online Seminars including
Exercises for Statistical Writing workshop are here.
Remote and email consulting is available to UCLA graduate students who are working on their thesis, dissertation or to-be-published paper; please see Remote Statistical Consulting for information and hours. Also, please review our Statistical Consulting Services to learn more about what services we provide. Please note that we cannot read over your entire results section and make comments. Rather, we can answer specific questions that you might have about interpretation, wording, etc. If you would like to hire a statistics tutor, we have a list of people that we can share with you.